Co-Authored by: Pradeepta Sahu, DevOps Lead & Sidharth Parida, DevOps Engineer
When enterprises require more control over the components of their applications used, they move away from infrastructure management by eliminating SaaS-based infrastructure (with EC2) and migrating to automated Containers Services (CaaS). Through this migration to CaaS, companies gain flexibility and agility in DevOps because their contracted structure is not associated with a specific machine. This approach uses AWS Cloud resources like AWS Fargate for Amazon EKS to overcome the disadvantages of OS virtualization (i.e. Running Multiple OSs on a physical server), by introducing containers that give teams more control over the software delivery model.
Our Idexcel DevOps team has created a strategic solution using AWS Fargate for Amazon EKS that reduces development costs on new projects. This managed Microservices-based platform breaks down the industry burden of managing into more easily managed Serverless Kubernetes infrastructures. Why are these monolithic applications such a challenge? They are tightly coupled and entangled as an application evolves, making it difficult to isolate services for purposes such as independent scaling or code maintainability. So, a single point of failure would shut down the entire production until the necessary recovery actions are taken.
Since SaaS-based applications are fully managed Monolithic and control lies with the primary cloud provider, organizations are realizing the critical need to have more control of their infrastructure in the cloud. AWS Fargate delivers serverless container capabilities to Amazon EKS, which combines the best of both Serverless and Container benefits. With Serverless capabilities, developers don’t need to worry about purchasing, provisioning, and managing backend servers. Serverless architecture is also indefinitely scalable and easy to deploy with plug-and-play features. This integration between Fargate and EKS enables Kubernetes users to transform a standard pod definition into a Fargate deployment. Fargate is a serverless compute engine for containers that removes the need to provision and manage servers. It allocates the right amount of compute needed for optimal performance by eliminating the need to choose instances and automatically scaling the cluster capacity.
This means that EKS can support Fargate to provide serverless compute engines for containers by reducing provisioning, configuring, or scaling virtual machine groups to run containers. EKS does this by facilitating the existing nodes (managed nodes) to communicate with Fargate pods in an existing cluster that already has worker nodes associated with it.
Major Advantages of Fargate Managed Nodes
Faster DevOps Cycle = Faster time to market: By removing the contracted structure tied to specific machines and leveraging cloud resources, DevOps teams increase deployment agility and flexibility to launch solutions at a quicker pace.
Increased Security: Fargate and EKS are both AWS Managed Services that provide serverless and Kubernetes configuration management, safely and securely within the AWS ecosystem.
Combines the Best of Both Serverless & Containers: Fargate provides serverless computing with Containers. This combination of technologies enables developers to build applications with less costly overhead and greater flexibility than applications hosted on traditional servers or virtual machines.
Enhanced Flexibility and Scalability: Any Kubernetes microservices application can be migrated to EKS easily with infinite scalable serverless capability.
Reduced Costs: With Containerization, overhead costs are reduced through the elimination of on-premises servers, network equipment, maintenance of server management maintenance, and patch/cluster management.
In this next section, we’ll illustrate how to control the resource configuration in Fargate Nodes in Amazon EKS and administer the Kubernetes Nodes on AWS Fargate without needing to stand up or maintain a separate Kubernetes control plane.
Kubernetes Cluster Management in Amazon Cloud
Amazon EKS runs Kubernetes control plane instances across multiple Availability Zones to ensure high availability. Amazon EKS automatically detects and replaces unhealthy control plane instances and provides automated version upgrades/patching for them.
Amazon EKS is also integrated with many other available AWS services to provide scalability and security for applications, including the following:
- Amazon ECR for container images
- Elastic Load Balancing for load distribution
- IAM for authentication
- Amazon VPC for isolation
Fargate with Managed Nodes
The goal achieved through this solution is a more flexible and controlled Kubernetes infrastructure to make sure pods on the worker nodes can communicate freely with the pods running on Fargate. These Fargate pods are automatically configured to use the cluster security group for the cluster they are associated with. Part of this includes making sure that any existing worker nodes in the cluster can send and receive traffic to and from the cluster security group. Managed node groups are automatically configured to use the cluster security group, alleviating the need to modify or check for compatibility.
Our Solution Architecture
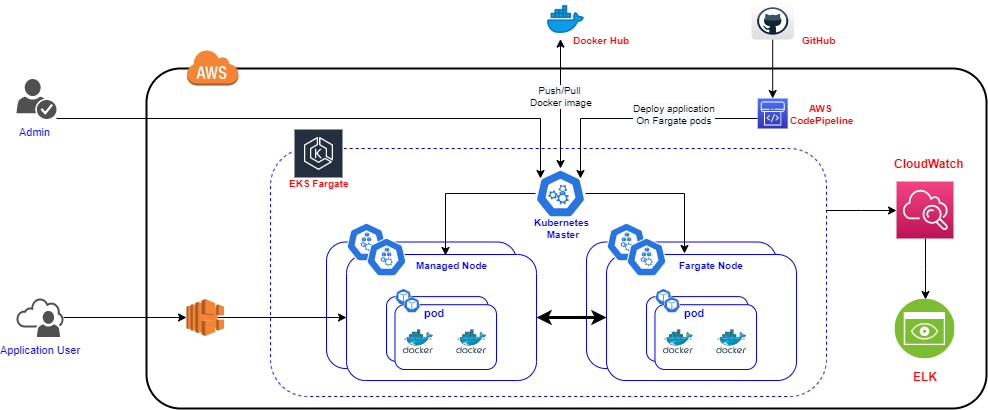
1. Create the Managed Node Cluster
Prerequisites: Install and configure the binaries that need to create and manage an Amazon EKS cluster as below:
– Latest AWS CLI
– Command-line utility tool eksctl
– Configure Command-line utility kubectl for Amazon EKS
Reference: https://docs.aws.amazon.com/eks/latest/userguide/getting-started-eksctl.html
Create the Managed node group cluster with the eksctl command line utility following the below command.

2. Create a Fargate Pod Execution Role
When the cluster creates pods on AWS Fargate, the pods need to make calls to AWS APIs to perform tasks like pulling container images from the Amazon ECR/DockerHub Registry The Amazon EKS pod execution role provides the IAM permissions to do these tasks.
Note: To create the cluster, use the eksctl –fargate option to create the necessary profiles and pod execution role for the cluster. Note: If the cluster already has a pod execution role, skip this step to Create a Fargate Profile.
With a Fargate profile, a pod execution role is specified to use with the pods. This role is added to the cluster’s Kubernetes Role Based Access Control (RBAC) for authorization. This allows the kubelet that is running on the Fargate infrastructure to register with the Amazon EKS cluster so that it can appear in the cluster as a node.
The RBAC role can be setup by following these steps:
- Open the IAM in AWS Console: https://console.aws.amazon.com/iam/
- Choose Roles, then Create role.
- Choose EKS from the list of services, EKS – Fargate pod for your use case, and then Next: Permissions.
- Choose Next: Tags.
- (Optional) Add metadata to the role by attaching tags as key–value pairs. Choose Next: Review.
- For Role name, enter a unique name for the role, such as AmazonEKSFargatePodExecutionRole, then choose Create role
3. Create a Fargate Profile for the Cluster
Before scheduling pods running on Fargate in the cluster, a Fargate profile need to be defined that specifies which pods should use Fargate when they are launched.
Note: If we created the cluster with eksctl using the –fargate option, then a Fargate profile has already been created for the cluster with selectors for all pods in the kube-system and default namespaces. Use the following procedure to create Fargate profiles for any other namespaces you would like to use with Fargate.
Create the Fargate profile with the following eksctl command, replacing the <<variable text>> with the own values. Specify a namespace (labels option is not required).
$ eksctl create fargateprofile –cluster <<cluster_name>> –name <<fargate_profile_name>> –namespace <<kubernetes_namespace>> –labels key=value

4. Deploy the sample web application to EKS Cluster
To launch an app in EKS cluster, we need to deploy a deployment file and a service file. We then launch the deployment and the service in the EKS cluster.
Example:
$ kubectl apply -f <<deployment_file.yaml>>
$ kubectl apply -f <<deployment-service.yaml>>
The above creates a LoadBalancer to access the public part of the cluster.
After that, the details of the running service in the cluster can be viewed.
Example:
$ kubectl get svc <<deployment-service>> -o yaml
Observation:
Verify that the hostname/loadbalancer created as it is configured in the <<deployment-service.yaml>>.
Now the service can be accessed with the hostname/loadbalancer on the browser.
Simply type the respective hostname/loadbalancer in the browser to verify that the application is up and running.
Streaming CloudWatch Logs Data to Amazon ElasticSearch Service
Amazon ElasticSearch Service (Amazon ES) is a managed service that makes it easy to deploy, operate, and scale ElasticSearch clusters in the AWS Cloud. ElasticSearch is a popular open-source search and analytics engine for use cases such as log analytics, real-time application monitoring, and clickstream analysis. Kibana is a popular open-source visualization tool designed to work with ElasticSearch. Amazon ES provides installation of Kibana with every Amazon ES domain.
Configure ELK with EKS Fargate
– Configure a log Group by following the steps provided by AWS at Log Group
– Subscribe the Log Group in CloudWatch, to stream data into the Amazon EKS
EKS Fargate is a robust platform that provides high availability and controlled maintainability in a secure environment. Because it runs the Kubernetes management infrastructure across multiple AWS Availability Zones, it automatically detects and replaces unhealthy control plane nodes, providing on-demand upgrades and patching with no downtime. This approach enables organizations to reduce time-to-market and remove the cumbersome burdens of patching, scaling, or securing a Kubernetes cluster in the cloud. Looking to explore this solution further or implement EKS Fargate Managed Nodes for your IT ecosystem? Connect with an Idexcel Expert today!





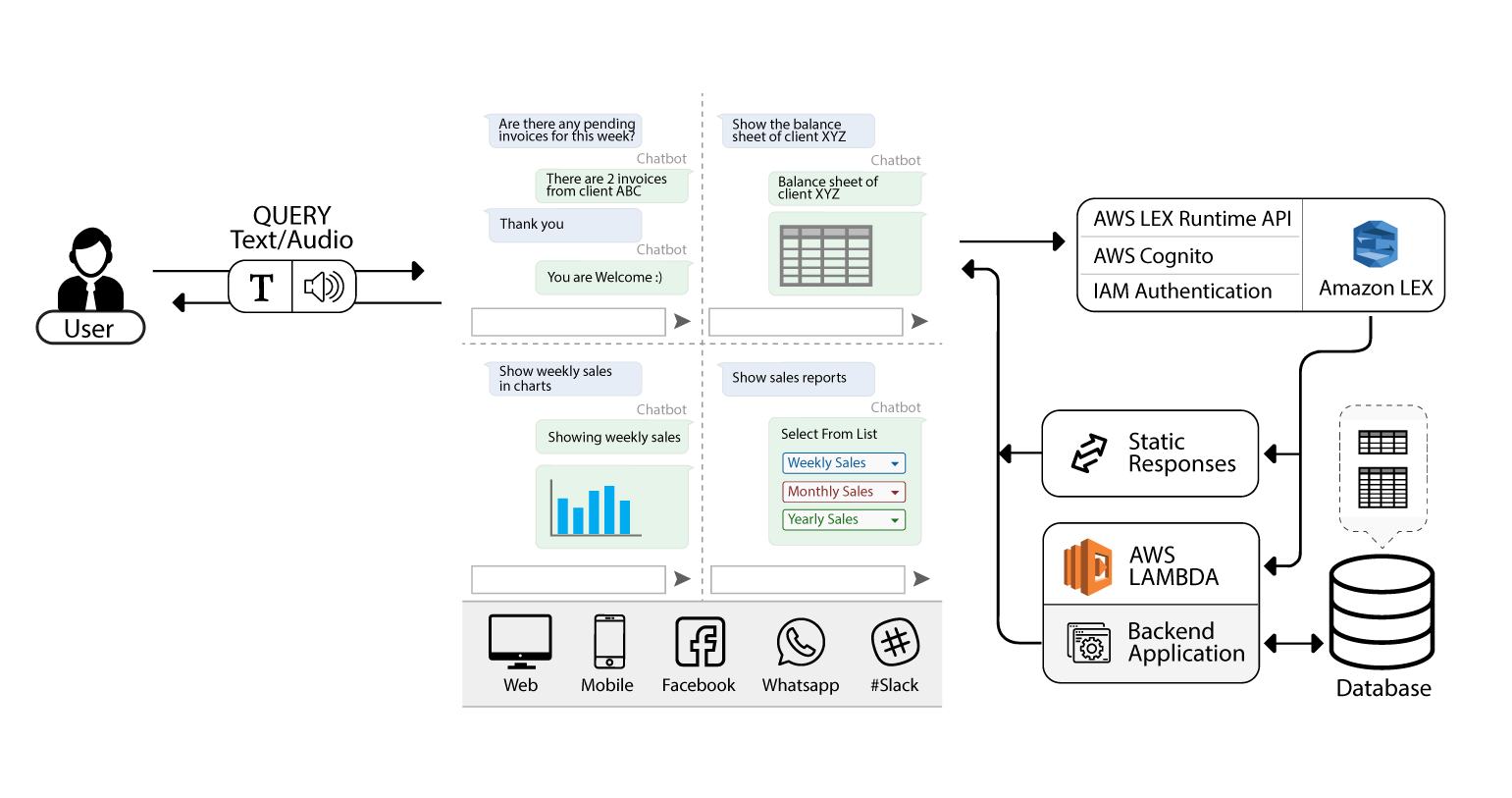
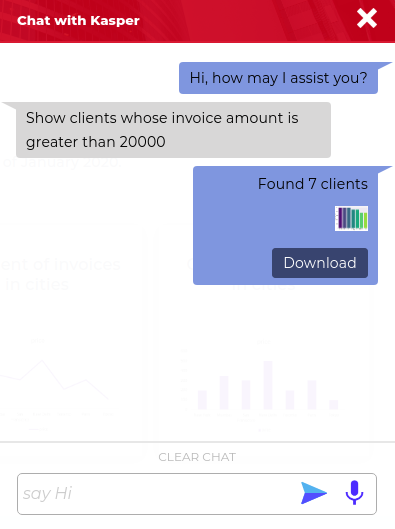
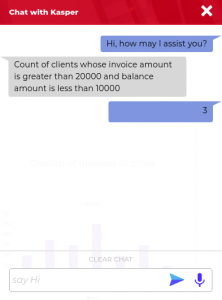 There are instances where users might want to know about a sum or count or any other single value response. For example, an inquiry might be “count the number of clients whose due date is within 2 weeks” or “sum of the invoice amount of all clients“. The responses of these queries will be just a single value eg. “10,000”.
There are instances where users might want to know about a sum or count or any other single value response. For example, an inquiry might be “count the number of clients whose due date is within 2 weeks” or “sum of the invoice amount of all clients“. The responses of these queries will be just a single value eg. “10,000”.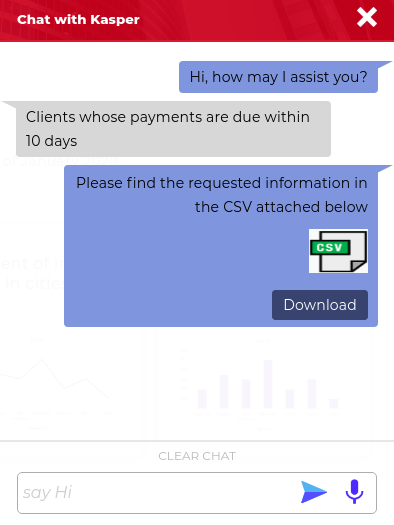
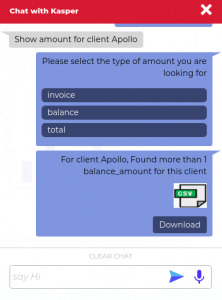 The third type of response are response cards – a response to clarify the intention of the user. Suppose the user asks an ambiguous question like this “what is the amount of Apollo Inc. “. The chatbot will find the query to be missing some keywords because the user did not specify the type of amount (either invoice amount or balance amount). Kasper then prompts back with a list of possible options, so the user can select the appropriate option and receive the accurate result.
The third type of response are response cards – a response to clarify the intention of the user. Suppose the user asks an ambiguous question like this “what is the amount of Apollo Inc. “. The chatbot will find the query to be missing some keywords because the user did not specify the type of amount (either invoice amount or balance amount). Kasper then prompts back with a list of possible options, so the user can select the appropriate option and receive the accurate result.
